Appearance
4. 코호트 설계
코호트 설계(cohort design)은 분석 목적에 따라 연구 대상 샘플을 정의하고 그룹화하는 과정입니다. 연구자는 코호트 설계를 통해 분석에 사용할 샘플을 선택하고, 비교 기준에 따라 그룹을 구성할 수 있습니다. 연구자는 유전체 데이터 및 임상 표현형 정보를 기반으로 코호트를 설계할 수 있으며, 설계된 코호트는 이후 수행되는 변이 분석, 발현 분석, 비교 분석 등의 입력 조건으로 활용할 수 있습니다. 코호트 설계는 분석 결과의 정확성과 신뢰성에 직접적인 영향을 미치는 단계이므로, 연구 목적에 적합한 샘플 및 비교 구조를 명확하게 설정하여야 합니다.
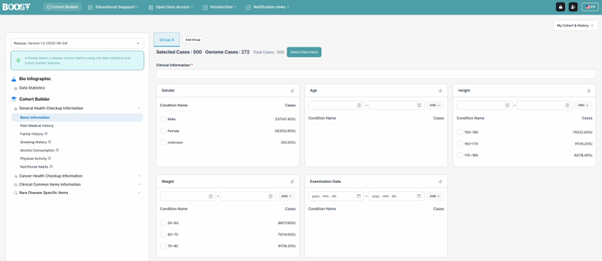
4.1 코호트 설계 개요
4.1.1 코호트 정의 및 필요성
코호트란 공통된 특성 또는 조건을 기반으로 구성된 연구 대상 집단을 의미합니다. 코호트는 유전체 데이터 및 다양한 메타데이터를 기준으로 샘플을 분류한 분석 단위로 정의될 수 있습니다. 코호트 설계는 분석 목적에 적합한 비교 구조를 구성하기 위해 필요한 단계입니다. 샘플의 분류 기준 및 비교 조건에 따라 분석 결과와 해석 방향이 달라질 수 있으며, 연구 목적에 부합하는 샘플을 선정하고 그룹을 명확하게 정의하는 과정이 요구됩니다. 또한 분석 대상 샘플의 일관성을 유지하고, 비교 분석의 기준을 명확히 설정하기 위한 기반 정보를 제공하며, 이를 통해 연구자는 분석 결과의 재현성과 신뢰성을 확보할 수 있습니다.
4.1.2 설계 흐름
코호트 설계는 분석 목적 정의부터 그룹 구성 및 비교 조건 설정까지 단계적으로 수행됩니다. 연구자는 다음과 같이 코호트를 설계할 수 있습니다.
- 분석 목적 정의: 분석을 수행하기 전 연구 목적 및 분석 유형을 정의합니다. 분석 목적에 따라 필요한 샘플 구성 및 비교 방식이 달라질 수 있으며, 코호트 설계 이전에 분석 목표를 명확히 설정하여야 합니다.
- 샘플 선택: 시스템에 등록된 샘플 목록 및 메타데이터를 기반으로 분석 대상 샘플을 선택합니다. 연구자는 샘플명, 질환 정보, 조직 정보, 성별, 연령, 처리 조건, 수집 시점 등의 메타데이터를 활용하여 필요한 샘플을 검색 및 필터링 할 수 있습니다.
- 그룹 구성: 선택된 샘플을 연구 목적에 따라 그룹별로 분류합니다. 각 그룹은 비교 분석의 기본 단위로 사용되며, 동일 그룹 내 샘플은 공통된 특성을 가져야 합니다.
- 비교 조건 설정: 그룹 구성 완료 후 분석에 사용할 비교 조건을 설정합니다. 비교 조건은 reference 와 target 그룹을 지정하는 단계이며, 이후 분석 과정에서 비교 기준으로 활용할 수 있습니다.
- 코호트 검토 및 저장: 최종적으로 코호트 구성 정보를 검토하고 저장합니다. 검토 단계에서는 샘플 누락, 그룹 분류 , 메타데이터, 비교 조건 설정, 샘플 수와 같은 정보의 오류 여부를 확인하여야 합니다. 검토가 완료된 코호트는 이후 분석 워크플로우에서 입력 조건으로 활용할 수 있습니다.
4.2 데이터 항목 탐색
코호트 설계 이전 시스템에서 제공하는 데이터 항목 및 변수 정보를 확인하여야 합니다. 연구자는 데이터 항목을 통해 분석에 활용 가능한 데이터의 종류와 특성을 사전에 확인할 수 있으며, 연구 목적에 적합한 데이터 항목을 선택하여 코호트 설계 및 분석 과정에 활용할 수 있습니다. 해당 기능은 유전체 데이터, 임상 정보, 표현형 정보 및 기타 메타데이터 항목을 체계적으로 조회할 수 있도록 제공됩니다. 연구자는 데이터 항목명, 변수명 등 데이터 유형 및 정보를 확인함으로써 분석에 필요한 변수를 효율적으로 탐색할 수 있습니다.
4.2.1 데이터 항목 개요
데이터 항목은 시스템에서 제공하는 분석 대상 정보의 최소 단위로서 제공됩니다. 각 데이터 항목은 샘플 또는 대상자에 대한 표현형 정보, 인구통계 정보, 질환 검사 정보, 생활 습관과 같은 특정한 정보를 포함하고 있으며, 분석 수행 시 변수(variable)로 활용될 수 있습니다. 각 데이터 항목은 고유한 변수명과 설명 정보를 포함하고 있으며, 데이터 유형에 따라 연속형(continuous), 범주형(categorical), 이진수(binary), 날짜(date) 등의 형태로 구성될 수 있습니다.
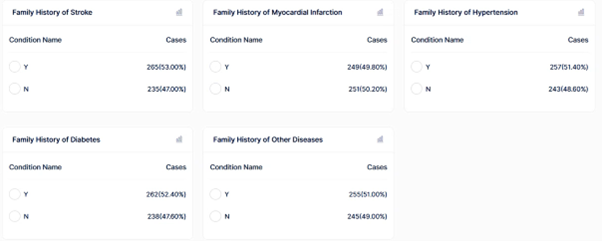
4.2.2 변수 설명 확인
연구자는 데이터 항목 내 상세 화면을 통해 변수에 대한 설명 정보를 확인할 수 있습니다. 변수 설명은 해당 데이터 항목이 의미하는 내용과 데이터 구성 방식을 설명하기 위한 정보입니다.
변수 설명 화면에서는 다음과 같은 정보를 포함합니다.
- 변수명
- 변수의 정의
- 단위 정보
- 데이터 유형
- 허용 값 범위
- 입력 또는 저장 형식
- 결측값
연구자는 변수 설명 정보를 통해 분석에 적합한 변수를 선택하고, 변수 해석 오류를 최소화할 수 있습니다. 또한 동일 변수에 대한 정의 및 사용 기준을 사전에 확인함으로써 분석 결과의 일관성을 유지할 수 있습니다.
4.3 조건 설정
조건 설정은 연구자가 원하는 대상 데이터를 선별하기 위하여 데이터 항목별 필터 조건을 지정하는 기능입니다. 연구자는 조건 설정 기능을 통해 특정 기준에 부합하는 대상자 또는 샘플만 선택하여 코호트 설계 및 분석에 활용할 수 있습니다. 조건 설정은 등록된 데이터 항목을 기반으로 수행되며, 각 항목의 데이터 유형에 따라 설정 가능한 조건 방식이 상이할 수 있습니다. 연구자는 단일 조건 또는 복합적인 조건을 이용하여 분석 목적에 적합한 데이터 집합을 구성할 수 있습니다.
4.3.1 조건 설정 항목 소개
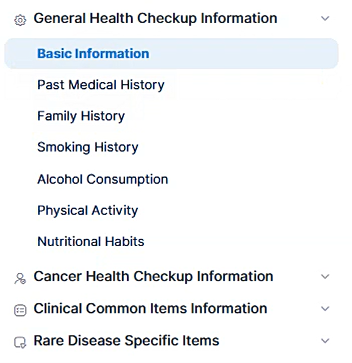
다음과 같은 데이터 항목에 대해 조건 설정을 포함할 수 있습니다.
- 건강 검진 정보
- 일반 정보
- 과거 진단 내역
- 가족력
- 흡연 이력
- 음주 정보
- 신체 능력
- 식습관 정보
- 암 검진 정보
- 과거 진단 내역
- 기본 검진 항목
- 기본 검진 측정 항목
- 희귀 질환 진단 정보
- 질환 분류 코드
4.4 필터 및 논리 조건 구성
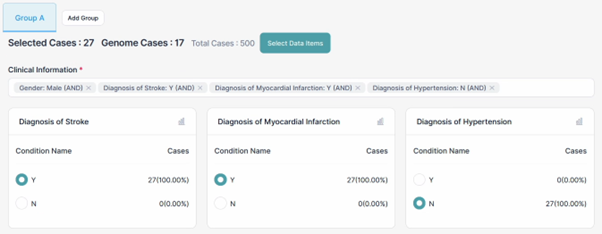
연구자는 복합 조건 기반의 데이터 필터링을 위하여 논리 조건(Logical condition) 기능을 이용할 수 있습니다. 연구자는 AND, OR, ADD, NOT 조건을 활용하여 분석 목적에 적합한 대상자를 보다 정교하게 선별할 수 있습니다. 논리 조건은 각 데이터 항목의 필터 조건을 연결하는 역할을 하며, 여러 조건을 조합하여 복합적인 검색 및 코호트 구성이 가능합니다. 필터링을 위한 조건은 코호트 빌더 내 임상정보 조건 설정 항목을 다중으로 선택하여 적용할 수 있습니다.
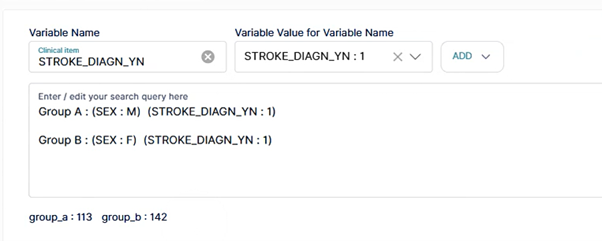
4.4.1 AND / OR 조건
○ AND 조건 AND 조건을 통해 지정한 모든 조건을 동시에 만족하는 데이터만 선택할 수 있습니다. 연결된 조건이 모두 참(True)인 경우 필터링 되어 결과에 포함되며, 공통된 특성을 가진 대상자를 선별할 때 사용할 수 있습니다. ''' 예) (SEX: M) AND (HEIGHT: >160 to < 170) AND (WEIGHT: > 60 to < 70) AND (STROKE_DIAGN_YN: 1) '''
○ OR 조건 OR 조건을 통해 지정한 조건 중 하나 이상을 만족하는 데이터를 선택할 수 있습니다. 연결된 조건 중 하나라도 참(True)인 경우 필터링 되어 결과에 포함되며, 다양한 조건을 포괄적으로 포함하고자 할 때 사용할 수 있습니다. ''' 예) (Body Temperature: 37.0 ~ 37.9) OR (Total Cholesterol: 180~210) '''
○ ADD 조건 ADD 조건은 새로운 필터 조건을 추가하는 기능입니다. 연구자는 기존 조건 그룹에 새로운 데이터 항목 조건을 추가하여 보다 세부적인 필터링을 수행할 수 있습니다. ADD 조건을 사용하여 복합 조건 구조를 단계적으로 확장하고, 조건 그룹을 유연하게 구성할 수 있습니다. 조건을 순차적으로 추가하여 다중 조건 기반의 코호트를 구성할 수 있으며, 추가된 조건은 설정된 논리 조건에 따라 결과에 반영됩니다.
○ NOT 조건 NOT 조건을 통해 연구자는 특정 조건에 해당하는 데이터를 제외할 수 있습니다. 지정한 조건이 참(True)인 데이터를 결과에서 제외합니다. NOT 조건은 특정 대상군을 분석에서 배제하고자 할 때 사용할 수 있습니다. ''' 예) (HEIGHT: > 150 to < 160) AND (WEIGHT : > 60 to < 70) NOT (CIG_SMOKE_YN : 2) '''
4.5 코호트 미리보기
연구자가 설정한 필터 조건 및 논리 조건을 기반으로 현재 구성된 코호트의 예상 결과를 사전에 확인할 수 있습니다. 연구자는 설정한 논리 조건을 통해 코호트의 수를 미리 파악할 수 있으며, 이를 통해 조건 설정 결과를 검토하고, 분석 수행 전 대상자 수 및 데이터 분포 상태를 확인할 수 있습니다. 코호트 미리보기는 코호트 설계 시 조건 설정 과정과 연계되어 동작하며, 필터 조건 변경 시 결과가 실시간 또는 단계적으로 반영될 수 있습니다. 이를 통해 연구자는 연구 목적에 적합한 코호트가 구성되었는지 사전에 검토할 수 있습니다.
4.5.1 예상 대상자 수 확인
연구자는 현재 설정된 필터 조건을 만족하는 대상자 또는 샘플 수를 실시간으로 확인할 수 있습니다. 조건 설정 후 다음 사항으로 예상 대상자 수를 검토할 수 있습니다.
- 총 건수
- 현재 건수
- 유전체 건수
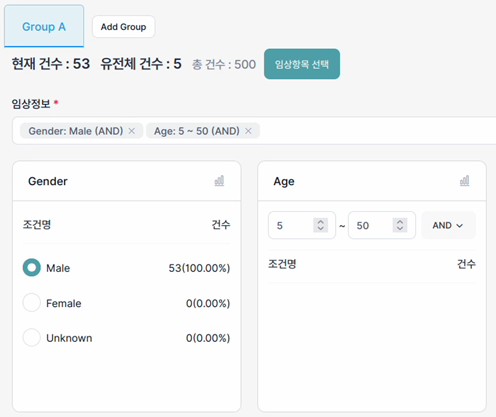
예상 대상자 수는 조건 변경 시 함께 갱신될 수 있으며, 연구자는 이를 기반으로 조건 범위를 조정하거나 추가 필터를 설정할 수 있습니다.
4.5.2 분포 확인
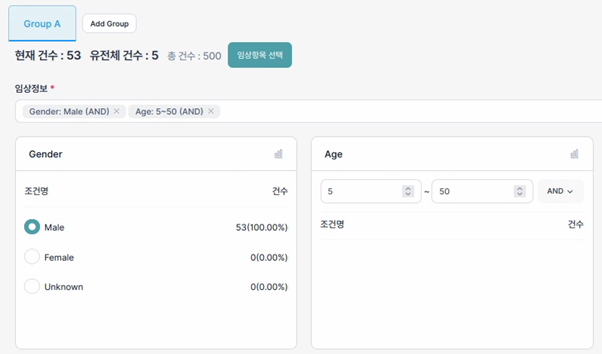
연구자는 현재 구성된 코호트 내 데이터의 분포 상태 및 통계를 시각적으로 확인할 수 있습니다. 연구자는 대상자의 특성 및 그룹 간 균형 상태를 확인하여 코호트 구성의 적합성을 검토할 수 있습니다. 코호트 설계를 위한 필터 조건 및 논리 조건을 설정한 후 “임상항목 선택”을 통하여 통계 지표 및 연구대상자 구조를 조회할 수 있습니다. 데이터 유형에 따라 분포 정보를 확인할 수 있으며, 분포 정보는 표, 막대 그래프, 원형 그래프 또는 히스토그램 형태로 제공될 수 있습니다.
- 참여자 정보
- 주요 임상 지표 요약(평균)
- 연구대상자 구조
- 연령 분포
- 성별 분포
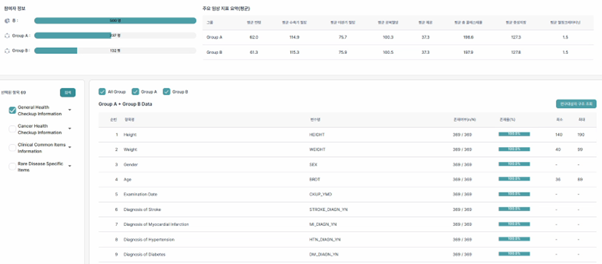
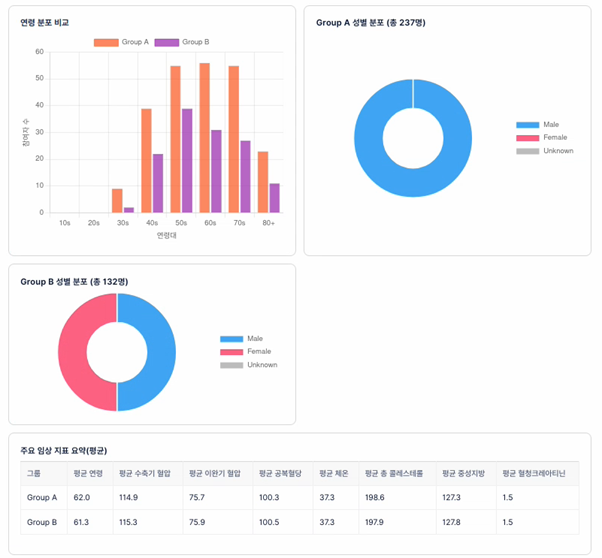
4.6 코호트 저장 및 버전 관리
연구자는 설계한 코호트를 저장하고, 이후 수정 사항 및 변경 이력을 관리할 수 있습니다. 연구자는 조건 설정 및 코호트 미리보기 단계를 통해 코호트 검토와 설계를 완료한 이후, 화면 내 [나의 코호트에 담기] 버튼을 통해 현재 코호트를 저장하고 이용할 수 있습니다. 저장된 코호트는 이후 분석 과정에서 재사용할 수 있으며, 동일 코호트에 대한 수정 및 버전 생성 이력을 관리할 수 있습니다.
4.6.1 버전 생성
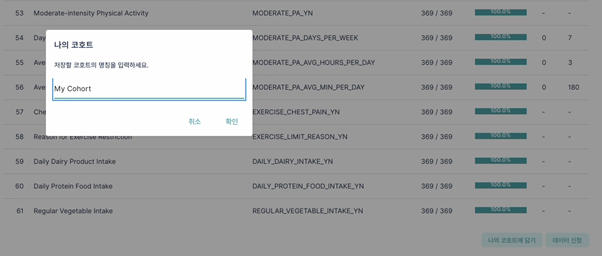
버전 생성은 저장된 코호트의 조건 구성 상태를 특정 시점 기준으로 저장하는 기능입니다. 연구자는 기존 코호트를 수정하거나 새로운 조건을 추가하는 경우, 별도의 버전으로 추가 저장하여 이전 설정 상태를 유지할 수 있습니다. [나의 코호트에 담기] 버튼을 클릭하여 저장할 코호트의 명칭을 입력하여 저장할 수 있으며, 코호트가 수정된 경우 새로운 명칭을 입력하여 버전에 따라 분석 조건을 보존하고 관리할 수 있습니다. 코호트 버전 생성을 통해 재현 가능한 분석 환경을 유지하고 버전별 비교를 수행할 수 있습니다.
4.6.2 쿼리 이력
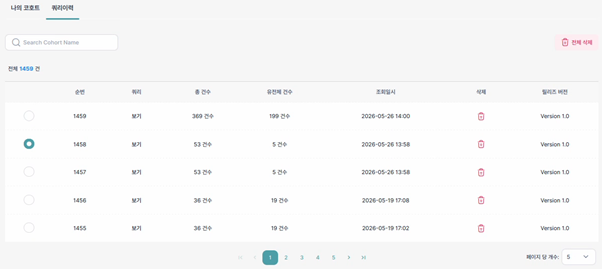
쿼리 이력 기능은 저장된 코호트에 대해 수행된 변경 내역을 기록 및 조회하는 기능입니다. 연구자는 쿼리 이력을 통해 코호트 조건 변경 사항 및 변경 시점을 확인 수 있습니다. 연구자는 코호트 변경 과정을 추적을 통해 분석 수행 시 사용된 조건 구성을 확인하고 코호트 관리의 일관성과 추적 가능성을 유지할 수 있습니다. 쿼리 이력에는 다음과 같은 정보가 기록될 수 있습니다.
- 필터 조건 및 논리 조건
- 유전체 건수
- 총 건수
- 조회 일시
- 릴리즈 버전